
What is Fine Tuning?
Adapting pre-trained foundation models to specific tasks by continuing training on curated datasets, improving performance while retaining general knowledge.
Understanding Fine-Tuning
When training AI and machine learning models for a specific purpose, data scientists and engineers have found it easier and less expensive to modify existing pretrained foundation large language models (LLMs) than to train new models from scratch. A foundation LLM is a powerful, general-purpose AI trained on vast datasets to understand and generate human-like text across a broad range of topics.
Fine-tuning is the process of adapting pretrained models by training them on smaller, task-specific datasets. It has become an essential part of the LLM development cycle.
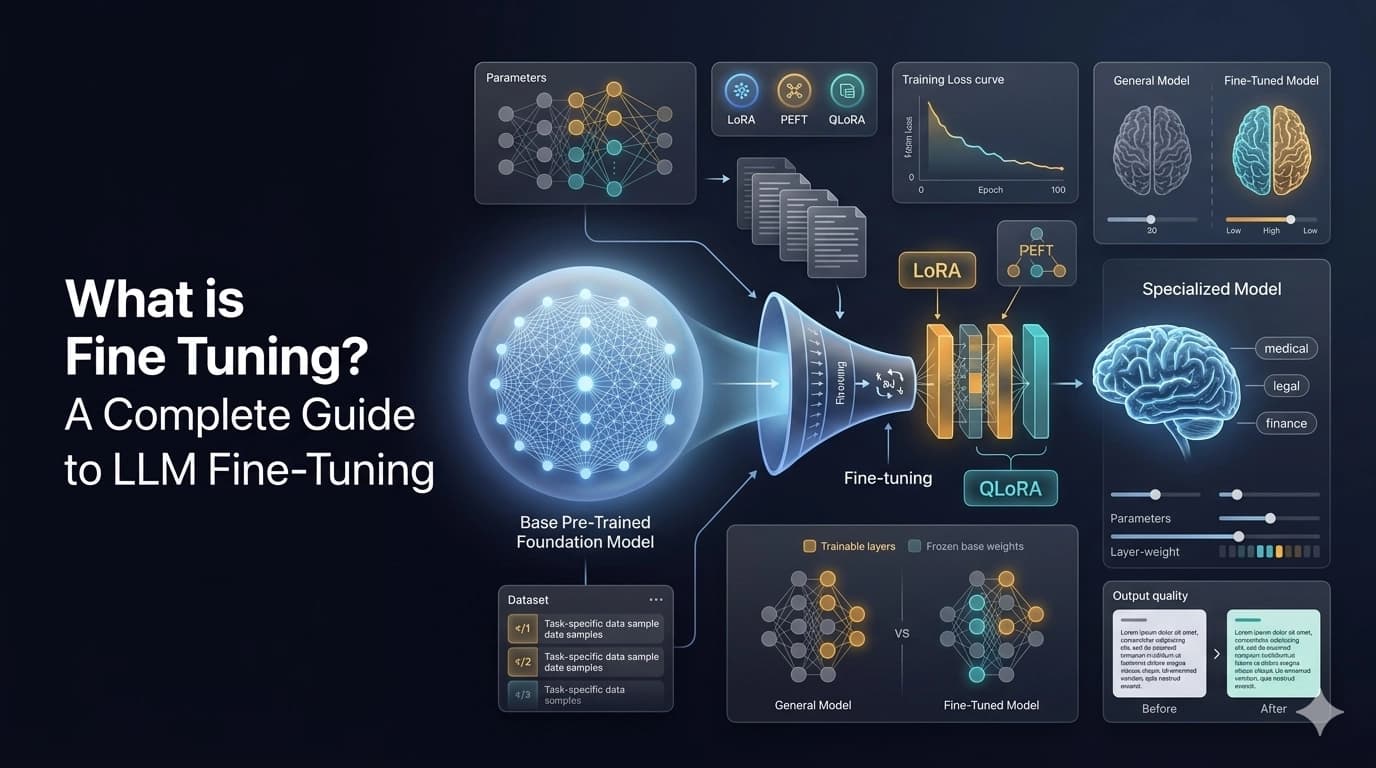
How Fine-Tuning LLMs Works
Pretrained large language models are trained on enormous amounts of data to make them good at understanding natural language. Fine-tuning improves their ability to perform specific tasks — such as sentiment analysis, question answering, or document summarization — with higher accuracy.
The Importance and Benefits of Fine-Tuning
Fine-tuning connects the intelligence in general-purpose LLMs to enterprise data, enabling organizations to adapt generative AI models to their unique business needs with higher specificity and relevance.
- Significantly reduces costly infrastructure investment
- Achieves faster time to market with reduced inference latency
- Reduces memory usage and speeds up training
- Keeps proprietary data secure within your infrastructure
Types of Fine-Tuning
- Full fine-tuning — Optimizes all layers of the neural network; best results but most resource-intensive
- Partial fine-tuning — Updates only select pretrained parameters critical to performance
- Additive fine-tuning — Adds extra parameters or layers, freezing existing pretrained weights
- Few-shot learning — Provides a few examples to guide the model when labeled data is limited
- Transfer learning — Applies general dataset knowledge to a specific or related task
Parameter-Efficient Fine-Tuning (PEFT)
PEFT is a suite of techniques that adapts large pretrained models while minimizing computational resources. Methods like LoRA and adapter-based fine-tuning introduce a small number of trainable parameters instead of updating the entire model. QLoRA further reduces memory load by using quantization.
When to Use Fine-Tuning
- Task-specific adaptation — Adapting to sentiment analysis, domain-specific text generation, etc.
- Bias mitigation — Reducing biases through balanced and representative training data
- Data security and compliance — Fine-tuning locally ensures sensitive data stays in your environment
- Limited data availability — Leveraging a pretrained model's knowledge with a smaller dataset
- Continuous learning — Periodically updating the model as data and requirements evolve
The Fine-Tuning Process
- Set up the environment — Use an ML platform that supports data lineage and parallel compute
- Select a base model — Choose from open source models that match your task characteristics
- Prepare your data — Transform data into a format suited for supervised fine-tuning
- Adjust model parameters — Apply RAG, PEFT, or standard fine-tuning techniques
- Train and evaluate — Assess progress with a validation dataset and iterate
Challenges and Best Practices
Common challenges include model drift, overfitting, bias amplification, and hyperparameter complexity. Best practices: leverage pretrained models, start small, use high-quality datasets, experiment with data formats, and tune hyperparameters carefully.
The Future of Fine-Tuning
Advances like LoRA streamline the process. Future integration may produce LLMs that generate their own training datasets. Multimodal fine-tuning is pushing boundaries — enabling models to integrate images, text, and speech into a single fine-tuned solution. Expect fine-tuned AI to become more integral to business operations across all sectors.